又一篇,奇富科技智能語音團隊論文登上國際頂會INTERSPEECH 2024快訊
此次被收錄的奇富科技智能語音團隊論文中Qifusion框架模型具有以下特點,使方言口音的語音識別誤差率降低了30%以上,方言識別準確率相對提升超35%。
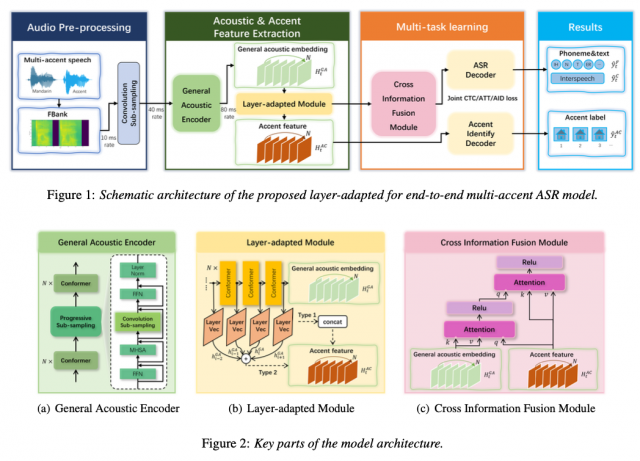
【TechWeb】7月10日消息,奇富科技智能語音團隊論文《Qifusion-Net:基于特征融合的流式/非流式端到端語音識別框架》(Qifusion-Net: Layer-adapted Stream/Non-stream Model for End-to-End Multi-Accent Speech Recognition)被全球語音與聲學頂級會議INTERSPEECH 2024收錄。

這是繼去年奇富科技團隊《Eden-TTS:一種簡單高效的非自回歸“端到端可微分”神經網絡的語音合成架構》論文之后的又一篇論文被該國際頂會認可。
資料顯示,INTERSPEECH由國際語音通訊協會(International Speech Communication Association, ISCA)創辦,是語音處理領域的頂級旗艦國際會議。作為全球最大的綜合性語音處理領域的科技盛會,歷屆INTERSPEECH會議都備受全球各地語音語言領域人士的廣泛關注。
此次被收錄的奇富科技智能語音團隊論文中Qifusion框架模型具有以下特點:
1.方言種類更豐富:
憑借自身在貸后場景及方言領域的豐富數據樣本,Qifusion框架模型在原有東北官話、膠遼官話、北京官話、冀魯官話、中原官話、江淮官話、蘭銀官話和西南官話等國內八種主流方言的基礎上,精準強化了四川、重慶、山東、河南、貴州、廣東、吉林、遼寧、黑龍江等用戶密集地區的方言識別能力。這使得平均識別準確率相對提升了25%,尤其在川渝地區,方言識別準確率相對提升超35%。
2.方言識別更精準:
Qifusion框架模型具備自動識別不同口音的能力,并能在時間維度上對解碼結果進行口音信息修正,使方言口音的語音識別誤差率降低了30%以上,整體語音識別字錯率降低了16%以上,顯著提升了用戶體驗。此外,在業內知名的Kespeech 開源方言數據集性能對比測試中,Qifusion字錯率刷新模型最低值,達到國內頂尖水平。
3.方言識別更高效:
Qifusion框架采用了創新的層自適應融合結構,能通過共享信息編碼模塊,更高效的提取方言信息。同時,該框架模型還支持即說即譯功能,能在無需知曉額外方言信息的前提下,對不同方言口音的音頻進行實時解碼,實現精準的識別和轉譯。這使得Qifusion框架在業務場景中能夠迅速準確地捕捉并響應用戶需求。
據悉,奇富科技智能語音團隊將受邀參與9月INTERSPEECH 2024科技盛會并發表主題報告,進一步分享其在語音識別領域的創新成果,與全球同行共探語音科技的未來。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
