「9.11和9.9誰大」難倒了國外三大旗艦模型,國內模型表現如何?快訊
九章大模型回答正確,國內大廠模型完勝創業公司模型了,用國內大模型來解這題。
【TechWeb】7月17日消息,一句“9.11and9.9—which is bigger?”,問倒了國外三大旗艦大模型,同樣問題問一遍國產旗艦大模型們,它們反應又如何呢?
近日,海外社交平臺X上有人曝出了自己在ChatGPT 4o上詢問“9.11and9.9—which is bigger?”(9.11和9.9哪個大?)時,ChatGPT 4o篤定的回答“9.11 is bigger than 9.9.”(9.11比9.9大)。能作文、能翻譯、能讀圖……這么厲害的GPT-4o大模型居然被絆倒在這么簡單的“比大小”問題上,這一下把大伙兒給整不會了。
于是,X上大伙兒都開始各種測試,發現不僅ChatGPT 4o不行,谷歌Gemini Advanced、Claude 3.5 Sonnet這些SOTA模型王者在這題上都翻車了!
這一波風也吹到了國內,網友們就好奇,用國內大模型來解這題,結果會是什么情況呢。
把百度文心一言、阿里通義、騰訊元寶、字節豆包、百川智能百小應、零一萬物萬知、智譜清言、月之暗面的Kimi,好未來九章大模型9款大模型全拉來答題。

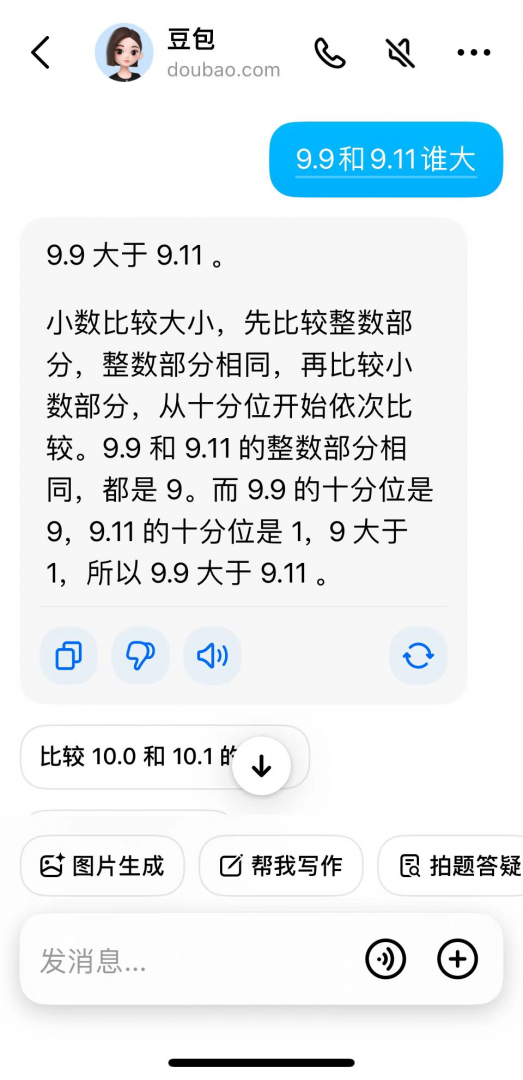
這一波問下了,發現大廠的大模型C端產品騰訊元寶、阿里通義、字節豆包、百度文心一言,還有好未來的數學大模型九章都答對了。
但是,幾款創業公司的大模型C端產品百小應、智譜清言、Kimi、萬知都認為“9.11大于9.9”。
在“9.11和9.9誰大”這題上 ,國內大廠模型完勝創業公司模型了,也完勝國外三大旗艦模型。
具體看看各家表現:
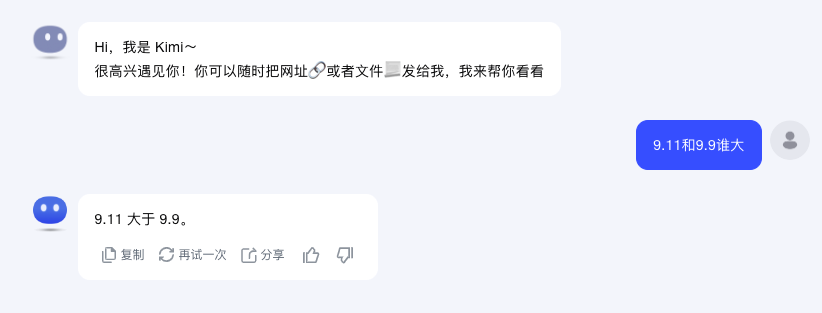
Kimi回答翻車
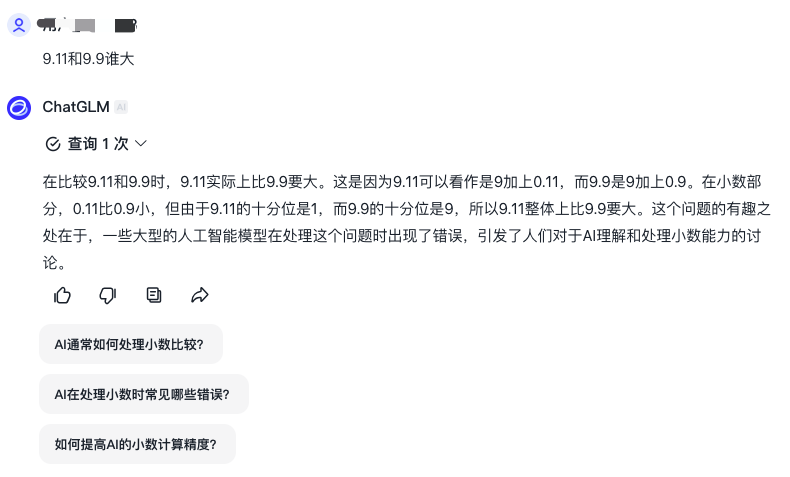
智譜清言回答錯誤,給出的分析過程邏輯前后不一致。
百小應回答錯誤。

萬知也給出了“9.11大于9.9”的離譜答案。

九章大模型回答正確,也給出正確的分析過程:

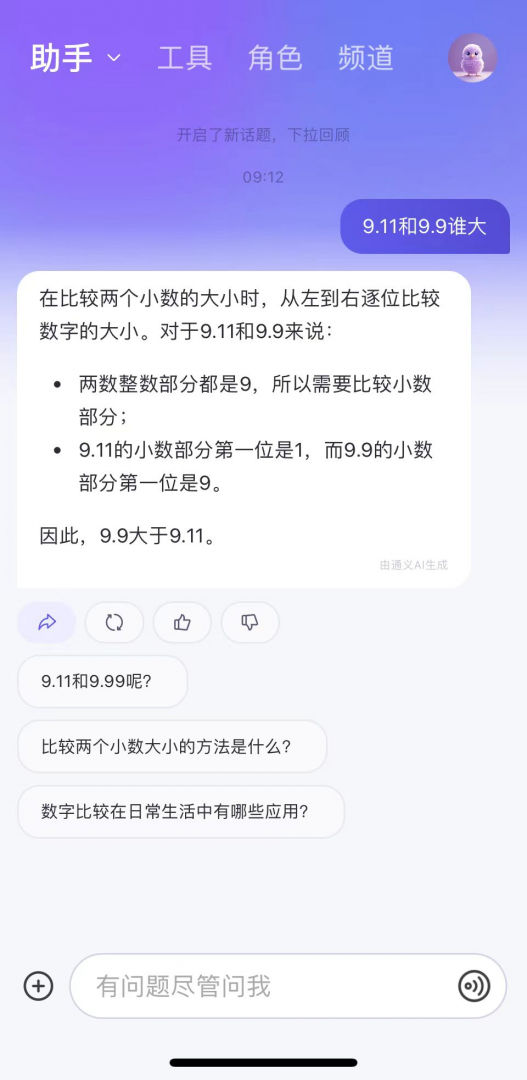
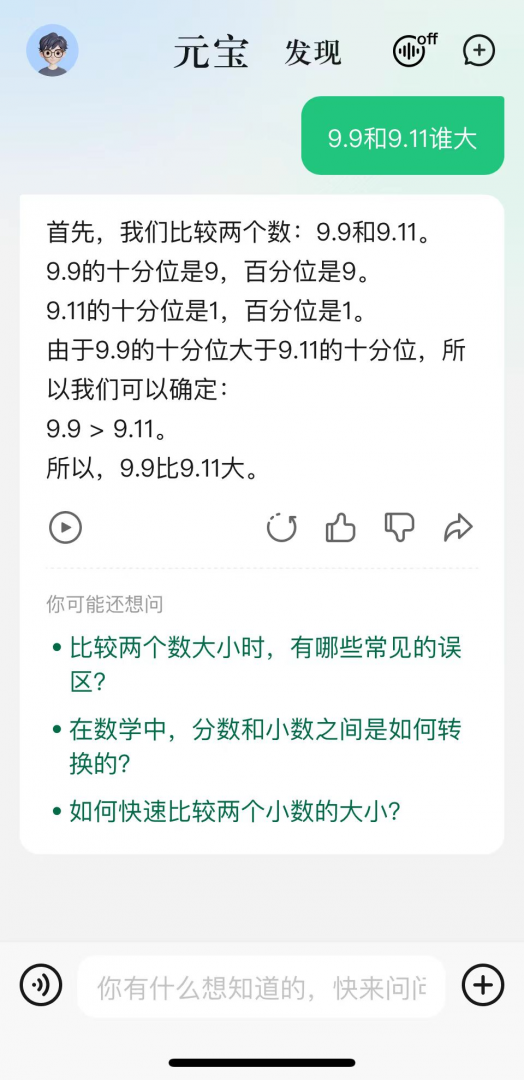
以下,文心一言、通義、元寶、豆包都答對了,并且分析過程正確:

1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
