騰訊云披露 4 月 8 日服務故障原因:云 API 異常持續近 87 分鐘快訊
酒店前臺發生故障會導致入住、續住等管理能力不可用,確保即使在云服務出現故障時,騰訊云官方微博下也有網友反饋服務故障。
IT之家 4 月 14 日消息,騰訊云官方公眾號今日發文,披露了 4 月 8 日服務大范圍故障的原因及細節。
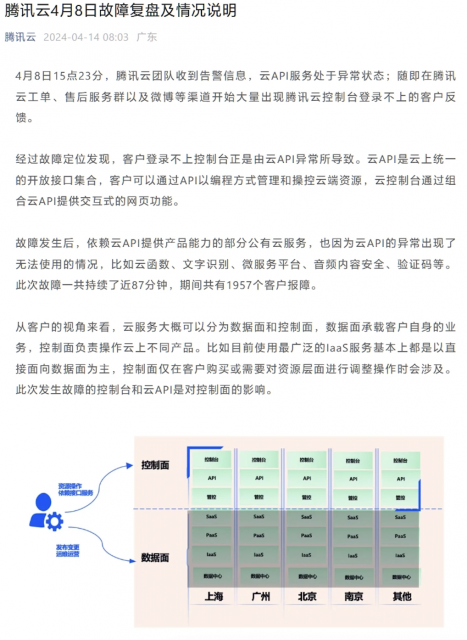
官方表示,經過故障定位發現,客戶登錄不上控制臺正是由云 API 異常所導致。云 API 是云上統一的開放接口集合,客戶可通過 API 以編程方式管理和操控云端資源,云控制臺通過組合云 API 提供交互式的網頁功能。
故障發生后,依賴云 API 提供產品能力的部分公有云服務也因此出現無法使用的情況,包括云函數、文字識別、微服務平臺、音頻內容安全、驗證碼等。此次故障一共持續了近 87 分鐘,期間共有 1957 個客戶報障。
騰訊云方面稱,若將云服務比作“酒店”,控制臺就相當于“前臺”,是統一的服務入口。“酒店前臺發生故障會導致入住、續住等管理能力不可用,但已入住的客房不受影響。”這次故障中客戶已經配置好的服務器等 IaaS 資源,包括已經部署運行的業務,沒有受到云 API 異常的影響。
官方披露了這次故障根本原因及改進措施如下:
綜合盤點這次故障,最根本的原因是在版本變更過程中,沒有有效執行沙箱驗證和預案演練,暴露了在變更管理上的不足,接下來將從以下幾個方面快速進行改進和完善,以減少故障的影響范圍和影響時長。
第一,提升系統韌性
1、定期執行預定的變更策略模擬演練,確保在真實故障發生時,能夠迅速切換到恢復模式,最小化服務中斷時間。
2、優化服務部署架構,通過分層架構、代碼審查和監控等手段, 避免 API 服務中潛在的循環依賴問題。
3、提供 API 服務逃生通道,當故障發生時,可供調用方快速切換。
第二,強化變更管理與保護措施
1、完善自動化測試用例庫,在系統變更前通過沙箱環境對變更內容進行嚴格驗證。
2、實施灰度發布策略,逐步推廣新功能或配置更改,按集群、可用區、地域逐步生效,以便在發現問題時能夠迅速回滾。
3、引入異常自動熔斷機制,當檢測到系統異常時,能夠立即中斷變更過程。
第三,增強故障響應與溝通能力
1、對故障處理流程進行全面升級,確保實時更新故障處理進度和預計恢復時間點,提升故障報告發布效率。
2、在對外發布的故障通知中,清晰闡述受影響的業務范圍、故障根因及預計修復時長,保持透明度。
3、優化騰訊云健康狀態看板(StatusPage)的信息展示邏輯,解除對云 API 等云服務的依賴,通過引入緩存和容災機制,確保即使在云服務出現故障時,能準確、及時地傳遞故障信息。
據IT之家4 月 8 日報道,當日下午騰訊云出現服務故障,接口響應報錯、內部服務錯誤,網頁顯示 504 錯誤。騰訊云官方微博下也有網友反饋服務故障,IP 來自全國多地。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
