GPT-o1模型實測:“物化生”水平超人類博士? 推理能力碾壓GPT-4o快訊
我們首先用一些之前大模型都愛翻車的簡單題目來測試一下o1系列的推理能力,測試一下競賽類題目o1系列模型的能力,也是OpenAI首款具備復雜推理能力的大模型。
TechWeb 文/卞海川
毫無預熱的情況下,Open AI于9月13日凌晨發布了o1系列的大模型,這是傳聞中內部代號為“草莓”的項目,也是OpenAI首款具備復雜推理能力的大模型。

與其前代模型相比,新模型o1擅長通用復雜推理,在物理、信息學等領域表現優異,OpenAI CEO奧特曼稱它是一種新范式的開始:可以進行通用復雜推理的人工智能。
OpenAI把新的模型發布稱為「預覽版」,強調o1系列仍處于早期階段。
作為早期模型,它尚不具備ChatGPT的許多有用功能,例如聯網搜索以及上傳文件和圖像。
雖然處于開發初期,但o1系列在競賽數學、編碼、科學等類目都有非常不錯的表現,其中競賽數學類甚至大幅領先GPT-4o。
你可以簡單理解為,o1系列模型是一個極度“偏科”的理工型人才。
根據官方的解釋,o1系列模型采取“思維鏈”的模式進行訓練,以此提升大模型的邏輯推理能力。
所以在回答問題之前,它會花更長時間思考,也就是說,o1系列并不追求信息輸出反饋的速度,而是更在乎推理結果的準確性。
為了更好的了解o1系列的能力,我們對它進行了一些簡單的測試。
我們首先用一些之前大模型都愛翻車的簡單題目來測試一下o1系列的推理能力。
“單詞strawberry里面到底有幾個r”
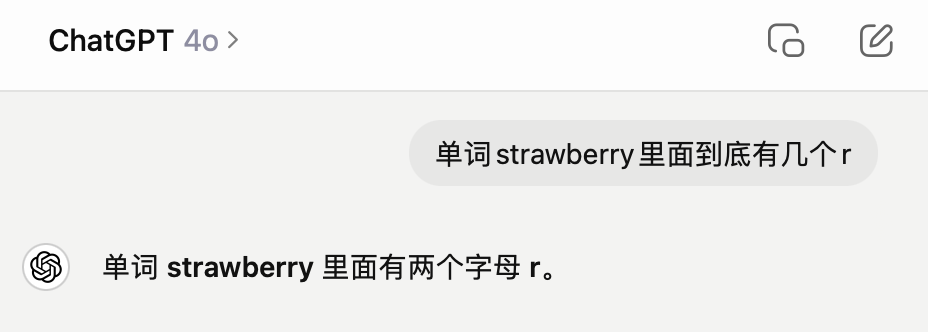
不出意外,GPT-4o依舊翻車,給出的答案是錯誤的。
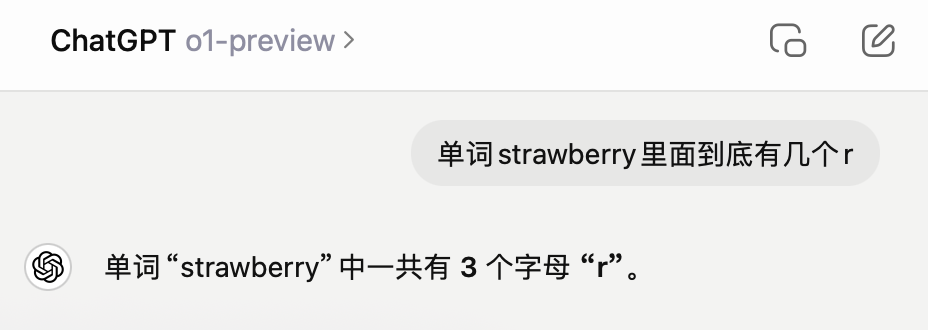
讓我們驚喜的是,GPT-o1的回答就非常準確,
“9.11和9.8誰更大?”
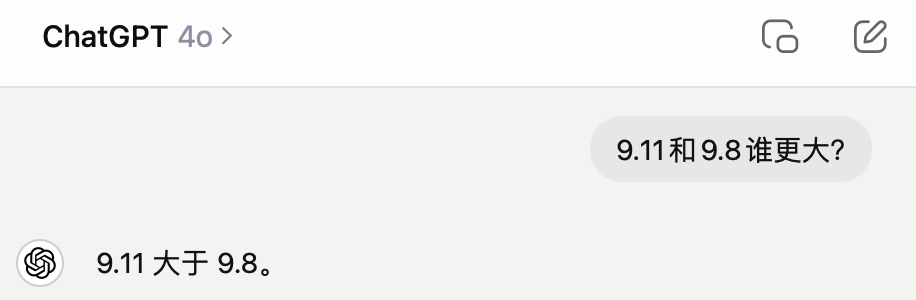
GPT-4o在1秒內回答,但是給出了錯誤答案。

難倒了一眾大模型的小數位比大小問題,o1系列沒有翻車,在等待了10多秒以后,o1給出的答案是正確的。
我們再來一些正常的推理題,選擇經典的小學奧數水平“空瓶換汽水”問題。
原題如下:“1元錢一瓶汽水,喝完后兩個空瓶換一瓶汽水,問:你有20元錢,最多可以喝到幾瓶汽水?”
很遺憾,在第一次回答的結果上,4o和o1系列都給出了錯誤的39瓶答案。
但區別在于,如果我告訴它正確的答案,o1系列會糾正自己的錯誤,給出新的解題思路,但GPT-4o依舊覺得自己的回答是正確的。


接下來我們把難度升級,測試一下競賽類題目o1系列模型的能力。
據 OpenAI 介紹,在測試中,o1系列模型在物理、化學和生物等具有挑戰性的基準任務上的表現達到了博士生的水平。

這一模型在數學和編碼方面表現出色。在國際數學奧林匹克(IMO)的資格考試中,GPT-4o 只正確解決了 13% 的問題,而 o1 模型的得分率則高達 83%。

o1系列模型的編碼能力也在競賽中得到了評估,在 Codeforces 競賽中達到了第 89 個百分點。
Open AI CEO奧特曼在剛剛結束的2024 IOI信息學奧賽題目中,o1的微調版本在每題嘗試50次條件下取得了213分,屬于人類選手中前49%的成績。也就是說,它已經超過了大多數人類數學天才!
如果允許它每道題嘗試10000次,就能獲得362.14分,高于金牌選手門檻,可獲得金牌。

我們選取了AIME 2023的真題,該數學競賽的題目難度比IMO稍低,但仍處于數學競賽題目難度前列。


經過測試,o1和4o給出了兩個完全不一樣的答案,雖然解題思路步驟我們沒看懂,但從官方給出的答案來看,o1的結果是正確的。
最后,我們來測試一下o1系列代碼能力,以經典的俄羅斯方塊小游戲作為考題。

我們給o1模型提了要求,然后將所有代碼復制運行,一字未改,成功實現俄羅斯方塊小游戲。

寫在最后
經過我們的簡單測試,o1系列模型的最大亮點是顯著增加了邏輯推理能力,以前GPT-4o回答不上來的問題,o1系列可以給出正確的解題思路,它已經不僅僅是簡單的生成答案,而是能夠提前規劃、思考,更接近人類的思維過程。尤其是在數學領域表現突出。
不過,它在特定領域的精確度與應對復雜對話的表現上仍有待進一步優化,在數據分析、編程和數學等重推理的類別中,人們更傾向于選擇o1-preview。但在一些自然語言任務中,GPT-4o更勝一籌。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
