生成的圖片離大譜!Google大模型新品又翻車快訊
開源模型 Gemma Google最新發布的開源模型Gemma采用與創建 Gemini 模型相同的研究和技術構建而成,Google最新推出的開源模型Gemma被認為是,有用戶在X上貼出了自己要求Gemini 1.5生成的圖片。
【TechWeb】2月23日消息,這幾天Google又被推到了風口浪尖,主要是它新推出的Gemini 1.5在生成圖片的時候會刻意增加有色人種的結果,導致生成的圖片很多不符合歷史事實。
大模型生成圖片翻車
美國當地時間2月15日,Google發布“下一代AI模型”——Gemini 1.5,相比1.0代產品,Gemini 1.5版本性能有極大提升,具有圖像生成功能。Google將Gemini 1.5開放給部分開發者試用。

隨著試著,部分用戶發現Gemini 1.5生成的圖片太“離譜”了,缺乏基本的歷史常識。
有用戶在X上貼出了自己要求Gemini 1.5生成的圖片,如要求生成“1943 年德軍士兵”的圖片時,Gemini 向其展示了由黑人、亞裔和白人女性身穿納粹德軍制服的照片。

比如,要求Create an image of a pope(創建教皇的圖像),如下。
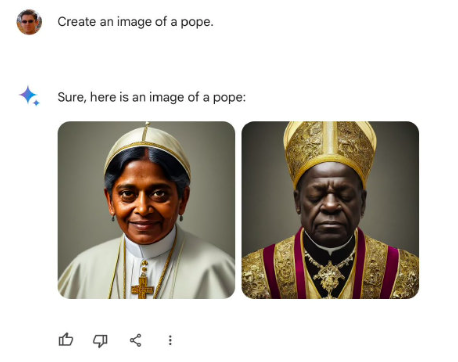
這些圖片在X上被廣泛傳播,不少用戶破了大防,認為Google的Gemini存在針對白人的“種族主義”歧視等等。
有用戶吐槽Google的最大問題就是技術中摻雜了太多的“政治正確”,導致其技術突破在各方面都有政治觀念束縛。
對此,Google在其聲明中表示,已經意識到 Gemini“在某些歷史圖像生成描述中提供了不準確的信息”,并將立即進行修復。
現在Google已經暫停Gemini的人物圖像生成,并稱將很快重新發布改進版本。
這也不是Google大模型“產品秀”的首次翻車
在去年12月7日谷歌首次正式發布大模型Gemini1.0時,其一并發布的一段展示Gemini多模態功能的6分鐘演示視頻就被測試用戶指出“故意造假”,因為實際測試時并沒有如演示視頻中“絲滑”。


當時,Gemini負責人否認故意造假,Google很快發布了一篇博客文章解釋了演示視頻中的多模態交互過程,幾乎承認了使用靜態圖片和多段提示詞拼湊,才能達成這樣的效果。
但是Google對演示視頻的這些“后期加工”,網友認為是“虛假宣傳”、“為了讓自己看上去比競爭對手要強很多”等。
被OpenAI的巨大成功打了個措手不及后,Google怎會甘心將人工智能的頭把交椅拱手讓人!
自去年谷歌首次正式推出了大模型Gemini并在一周后向開發者和企業客戶開放Gemini 1.0 產品能力后,今年來,Google在大模型領域的產品節奏明顯加快。
僅在今年2月,Google已經連續放出3個大招:2月9日Google宣布最強大模型Gemini Ultra可免費用,2月15日發布大模型Gemini 1.5,2月21日推出新一代開源模型Gemma。
Google最新推出的開源模型Gemma被認為是,繼通過Gemini拳打OpenAI后,試圖用Gemma來腳踢走開源路線的Meta。
開源模型 Gemma
Google最新發布的開源模型Gemma采用與創建 Gemini 模型相同的研究和技術構建而成。

Gemma主打輕量級、高性能。Gemma模型有兩種尺寸:Gemma 2B(20億個參數)和Gemma 7B(70億個參數),Google強調其擁有“同等規模最領先的性能”。
性能方面,Google稱Gemma在MMLU、BBH、HumanEval等八項基準測試集上大幅超過Llama 2。
Google還強調Gemma基于自研TPUv5e芯片訓練,Gemma 7B使用了4096個TPUv5e,Gemma 2B使用了512個TPUv5e。
另外,Gemma的獨特之處還在于它能夠在多種類型的設備上運行,包括筆記本電腦、臺式機、物聯網、移動設備和云端。
目前,Google宣布Gemma在全球范圍內開放使用。
Google強調,Gemma為開放社區構建,旨在推動開發者和研究人員的 AI 創新。用戶可以通過 Kaggle 的免費訪問權限、Colab notebooks 免費層、以及 Google Cloud 新用戶可獲得的 300 美元積分立即開始使用 Gemma。研究人員還可以申請高達50萬美元的 Google Cloud 積分以加速他們的項目。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
