DeepSeek代碼開源第三彈:DeepGEMM代碼庫,V3/R1的訓練推理動力快訊
DeepSeek團隊在H800上使用NVCC 12.8測試了DeepSeek-V3/R1推理中可能使用的所有形狀(包括預填充和解碼,DeepSeek在開源周的第三天宣布開放DeepGEMM代碼庫,DeepGEMM僅支持英偉達Hopper架構運算。
【TechWeb】2月26日消息,在宣布開源MLA解碼核FlashMLA以及DeepEP兩款代碼庫后,DeepSeek在開源周的第三天宣布開放DeepGEMM代碼庫。

DeepSeek介紹,DeepGEMM是專為簡潔高效的FP8通用矩陣乘法(GEMMs)而設計,它同時支持普通的和專家混合(MoE)分組的GEMM運算,為V3/R1訓練和推理提供動力支持。該庫使用CUDA編寫,在安裝過程中無需編譯,通過在運行時使用輕量級即時編譯模塊來編譯所有內核。

目前,DeepGEMM僅支持英偉達Hopper架構運算,為解決FP8張量核心累加不精確的問題,它采用了CUDA核心的兩級累加(提升)方法。該代碼庫設計非常簡潔,只有一個核心內核函數,代碼量約為300行。
盡管其設計輕巧,DeepGEMM的性能在各種矩陣形狀上與專家調優的庫相匹配或超越。
DeepSeek團隊在H800上使用NVCC 12.8測試了DeepSeek-V3/R1推理中可能使用的所有形狀(包括預填充和解碼,但沒有張量并行)。
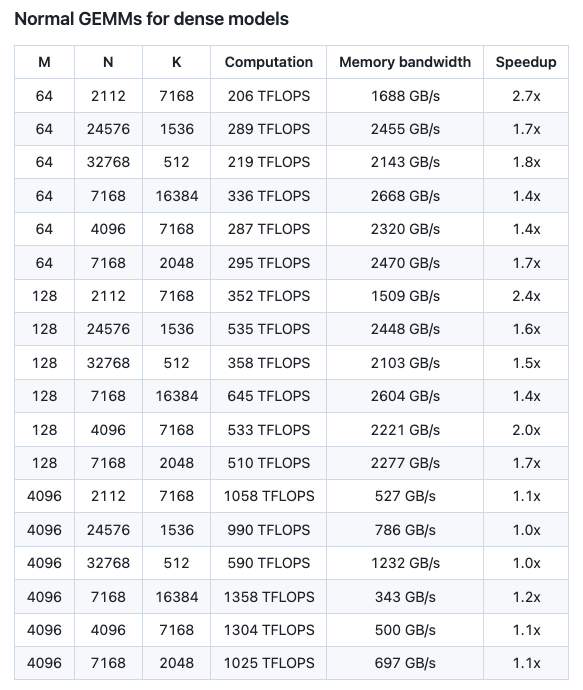
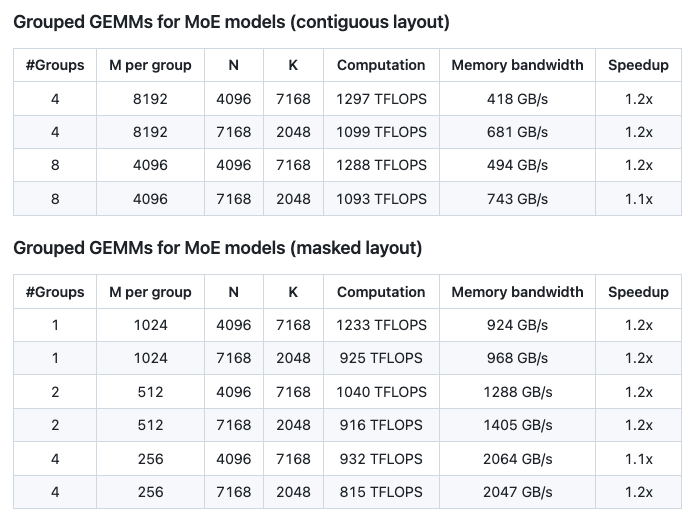
從測試結果來看,DeepGEMM計算性能最高可達1358 TFLOPS,內存寬帶最高可達2668 GB/s。與基于CUTLASS 3.6的優化實現相比,可提速最高可達2.7倍。另外,分組GEMM(MoE模型)中連續性布局、掩碼布局下可提速多達1.2倍。
另外,使用DeepGEMM需要的環境要求,包括:
* 必須支持Hopper架構的GPU,sm_90a
* Python 3.8及以上
* CUDA 12.3及以上(推薦12.8)
* PyTorch 2.1及以上
* CUTLASS 3.6及以上
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
