OpenAl采用智譜標(biāo)準(zhǔn)評測GPT-4.1系列大模型快訊
ComplexFuncBench是由智譜團隊提出的專用于評估大模型復(fù)雜函數(shù)調(diào)用能力的測試基準(zhǔn),ComplexFuncBench要求大模型對真實場景下的用戶需求進行細粒度理解,ComplexFuncBench主要評測大模型在128K的長上下文下進行多步帶約束的函數(shù)調(diào)用的能力。
【TechWeb】4月15日消息,OpenAI發(fā)布的了最新GPT-4.1系列大模型,其中在評測函數(shù)調(diào)用能力時采用了ComplexFuncBench。
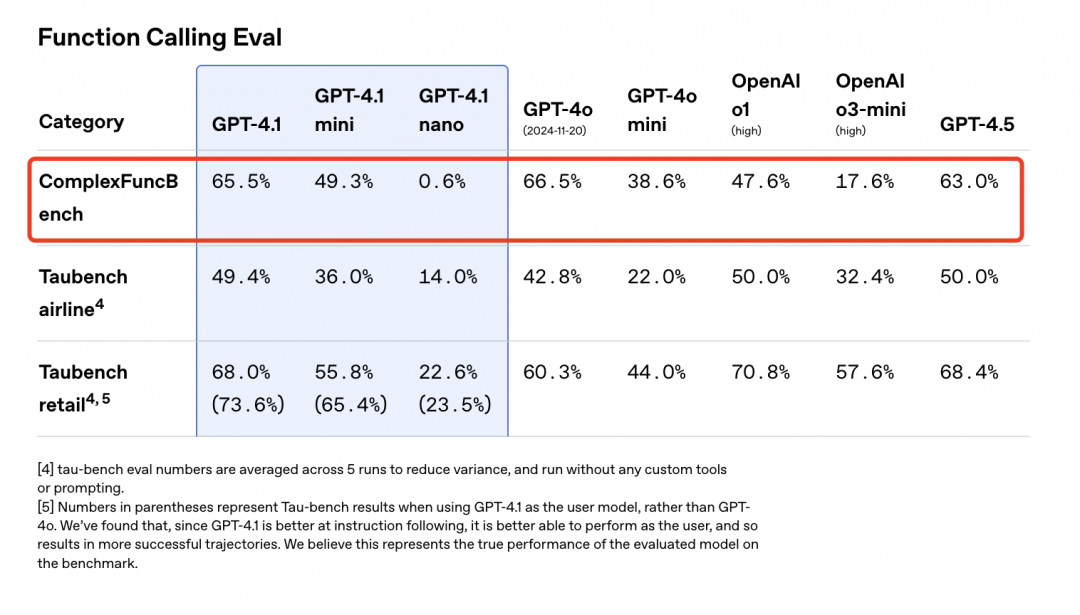
ComplexFuncBench是由智譜團隊提出的專用于評估大模型復(fù)雜函數(shù)調(diào)用能力的測試基準(zhǔn)。
據(jù)悉,ComplexFuncBench主要評測大模型在128K的長上下文下進行多步帶約束的函數(shù)調(diào)用的能力。相比于現(xiàn)有函數(shù)調(diào)用測試基準(zhǔn),ComplexFuncBench要求大模型對真實場景下的用戶需求進行細粒度理解,并在此基礎(chǔ)上進行多步帶推理的函數(shù)調(diào)用,這對模型的函數(shù)調(diào)用能力提出了更高的挑戰(zhàn)。(果青)
1.TMT觀察網(wǎng)遵循行業(yè)規(guī)范,任何轉(zhuǎn)載的稿件都會明確標(biāo)注作者和來源;
2.TMT觀察網(wǎng)的原創(chuàng)文章,請轉(zhuǎn)載時務(wù)必注明文章作者和"來源:TMT觀察網(wǎng)",不尊重原創(chuàng)的行為TMT觀察網(wǎng)或?qū)⒆肪控?zé)任;
3.作者投稿可能會經(jīng)TMT觀察網(wǎng)編輯修改或補充。
