生數科技下周全球發布Vidu Q1模型,強調高可控快訊
是一家專注于多模態生成式大模型與應用產品開發的高科技企業,生數科技2024年4月發布的視頻大模型Vidu可一鍵生成16秒1080P高清視頻,生數科技首創了基于Transformer的U-ViT架構。
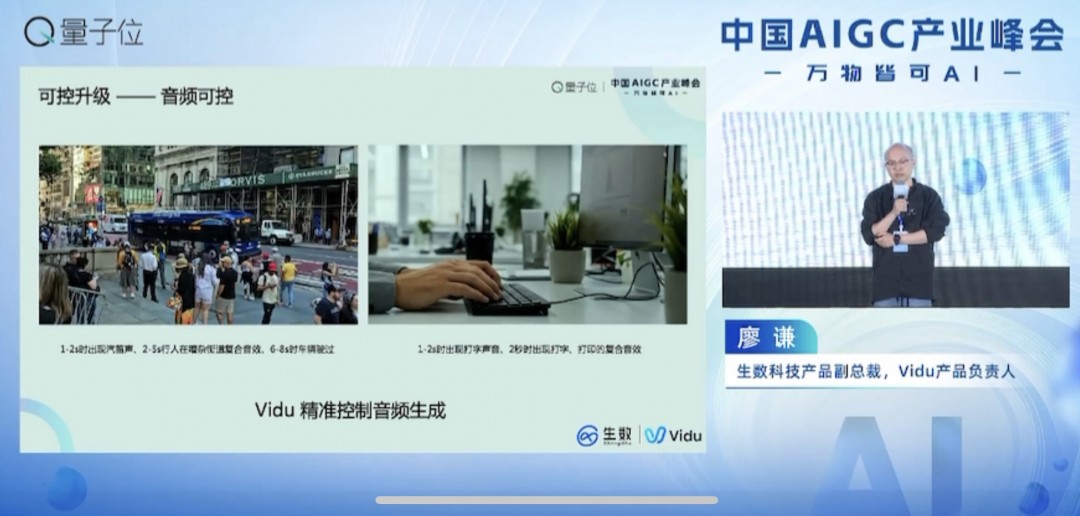
【TechWeb】4月16日消息,在今日舉辦的第三屆中國AIGC產業峰會上,生數科技產品副總裁、Vidu產品負責人廖謙透露,下周將全球發布即新的Vidu Q1模型,該大模型優化旨在大幅提升內容創作的可控性,尤其在位置控制、運動布局和音頻生成上,以更貼近人類審美和自然法則。

廖謙表示,Vidu Q1模型將推動多模態大模型時代的變革,將極大增強個性化內容生成能力,對社交、游戲、VR/AR等領域產生深遠影響。
生數科技(北京生數科技有限公司)成立于2023年3月,是一家專注于多模態生成式大模型與應用產品開發的高科技企業,核心團隊來自清華大學人工智能研究院。
生數科技首創了基于Transformer的U-ViT架構,融合了Diffusion模型與Transformer的優勢,支持多模態任務的統一建模。該架構在2023年開源的UniDiffuser模型中首次應用,成為全球首個基于Diffusion Transformer的多模態擴散模型,比Stable Diffusion 3采用的DiT架構領先一年。
基于U-ViT架構,生數科技2024年4月發布的視頻大模型Vidu可一鍵生成16秒1080P高清視頻,具備多鏡頭切換、高時空一致性和物理世界模擬能力,性能對標OpenAI的Sora。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
